BioMedLM 2.7B部署与测试 项目地址:
stanford-crfm/BioMedLM · Hugging Face
斯坦福-CRFM/BioMedLM (github.com)
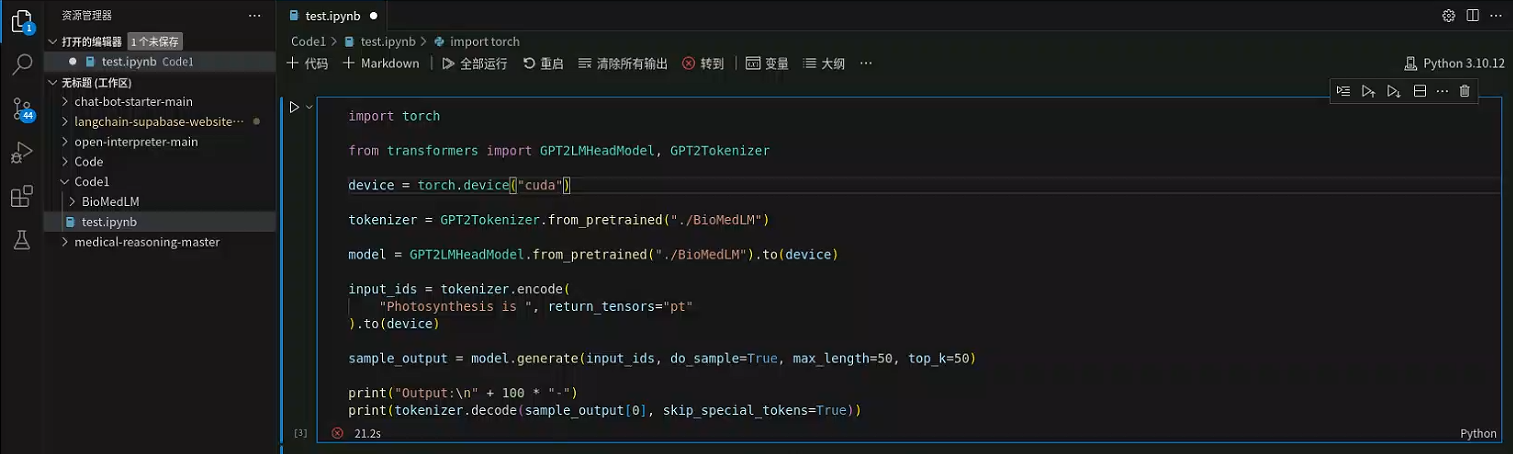
下载完模型后将模型的文件放到BioMedLM文件夹,在根文件夹外创建test.ipynb文件进行示例用法测试
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 import torchfrom transformers import GPT2LMHeadModel, GPT2Tokenizerdevice = torch.device("cuda" ) tokenizer = GPT2Tokenizer.from_pretrained("./BioMedLM" ) model = GPT2LMHeadModel.from_pretrained("./BioMedLM" ).to(device) input_ids = tokenizer.encode( "Photosynthesis is " , return_tensors="pt" ).to(device) sample_output = model.generate(input_ids, do_sample=True , max_length=50 , top_k=50 ) print ("Output:\n" + 100 * "-" )print (tokenizer.decode(sample_output[0 ], skip_special_tokens=True ))
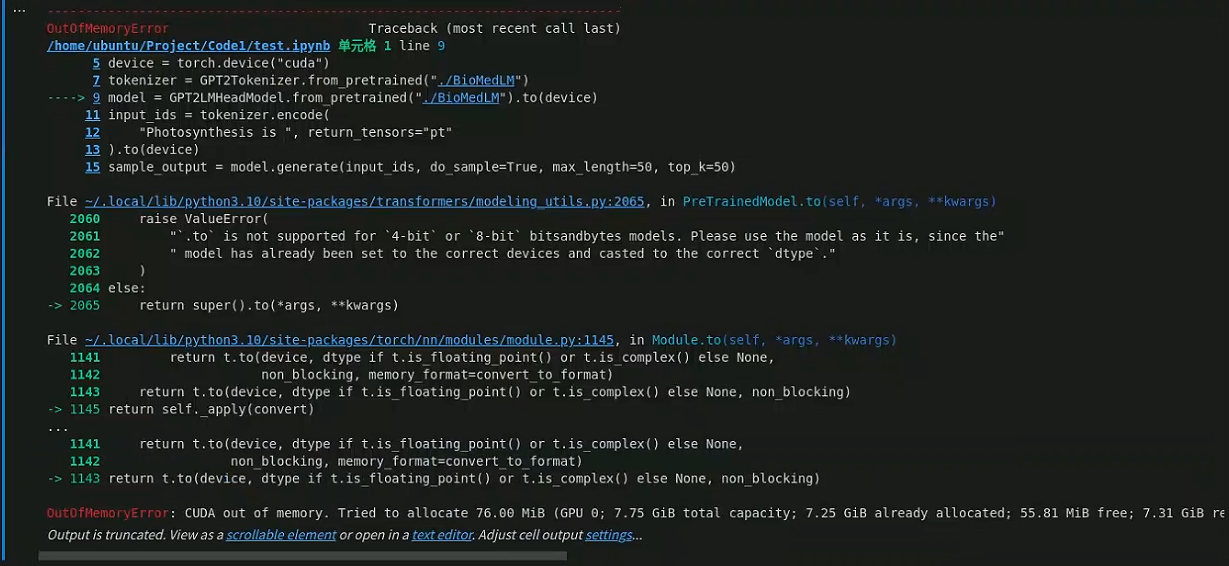
测试结果如下
出现的问题是GPU的显存不够,无法装载模型。
解决办法:
使用模型的半精度 (float16) : 转换模型为半精度可以大大减少显存使用量。使用transformersmodel.half()
禁用梯度计算 : 如果您只是进行模型推理,并不需要进行反向传播,可以使用torch.no_grad()
1 2 with torch.no_grad(): sample_output = model.generate(input_ids, do_sample=True , max_length=50 , top_k=50 )
修改后的代码如下
1 2 3 4 5 6 7 8 9 10 11 12 13 14 15 16 17 18 19 20 21 22 23 24 25 26 27 28 import torchfrom transformers import GPT2LMHeadModel, GPT2Tokenizerdevice = torch.device("cuda" ) tokenizer = GPT2Tokenizer.from_pretrained("./BioMedLM" ) model = GPT2LMHeadModel.from_pretrained("./BioMedLM" ) model.half().to(device) input_ids = tokenizer.encode( "Photosynthesis is " , return_tensors="pt" ).to(device) attention_mask = torch.ones_like(input_ids) with torch.no_grad(): sample_output = model.generate(input_ids, attention_mask=attention_mask, do_sample=True , max_length=50 , top_k=50 ) print ("Output:\n" + 100 * "-" )print (tokenizer.decode(sample_output[0 ], skip_special_tokens=True ))
对模型的提问:“Photosynthesis is ?“
输出的结果
Setting pad_token_id to eos_token_id:28895 for open-end generation.【回答】
Photosynthesis is ~99% of the total carbon fixed in plants, and CO~2~ assimilation occurs when the atmosphere is enriched with CO~2~. In addition to CO~2~, plants also take up and store other gases
输出的内容被截停是因为以下代码中max_length设置了50,且设置的大小与GPU显存有关。
with torch.no_grad():