
ChatGLM2 + LoRA微調部署及相关问题
ChatGLM2 + LoRA微調部署及相关问题
项目地址:
https://github.com/hiyouga/ChatGLM-Efficient-Tuning
模型地址:
https://github.com/THUDM/ChatGLM2-6B
整合包下载链接: https://caiyun.139.com/m/i?165CjeZSrqbR2 提取码:iJHs
整合包下载后解压成如下
【环境搭建】:本次部署所需的一些依赖或所需的系统软件
【教程.txt】 :模型的相关说明和微调的使用和修改方式等
【base_model】:作者提供的基础模型,省去了启动模型微调后自动下载模型的过程。可以将里面的文件移动到“ChatGLM2-6B main” 文件夹下的model文件夹中。如不提前下载,而在运行模型微调过程中等待程序进行下载,容易由于网络波动造成下载失败,模型微调终止。
【ChatGLM2-6B-main】:模型的根目录
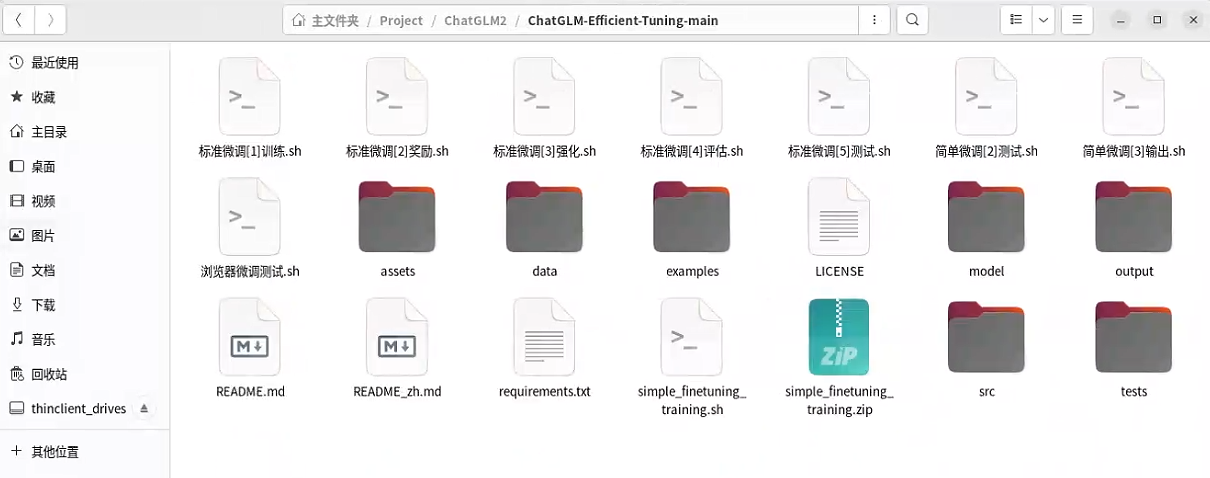
【ChatGLM-Efficient-Tuning】:模型微调的相关文件目录
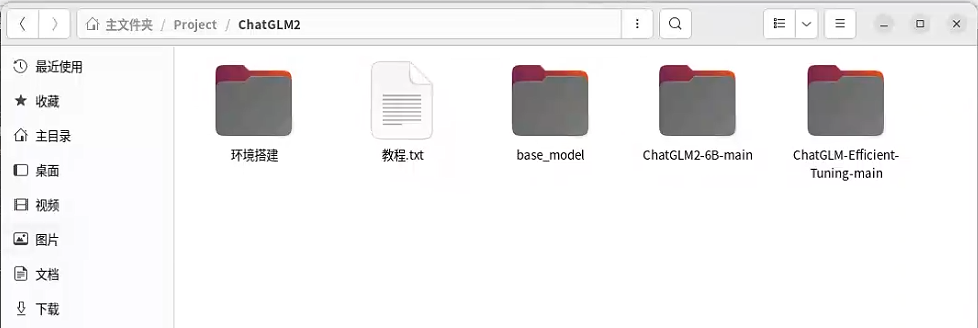
将base_model中的模型移动到ChatGLM-Efficient-Tuning-main文件夹下的model文件夹
【.sh】文件是模型微调的脚本文件
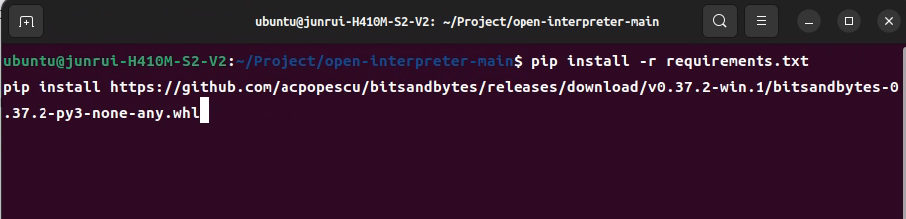
命令行进入到项目根目录下载依赖
pip install -r requirements.txtpip install [https://github.com/acpopescu/bitsandbytes/releases/download/v0.37.2-win.1/bitsandbytes-0.37.2-py3-none-any.whl](https://github.com/acpopescu/bitsandbytes/releases/download/v0.37.2-win.1/bitsandbytes-0.37.2-py3-none-any.whl)
尝试微调操作如下:
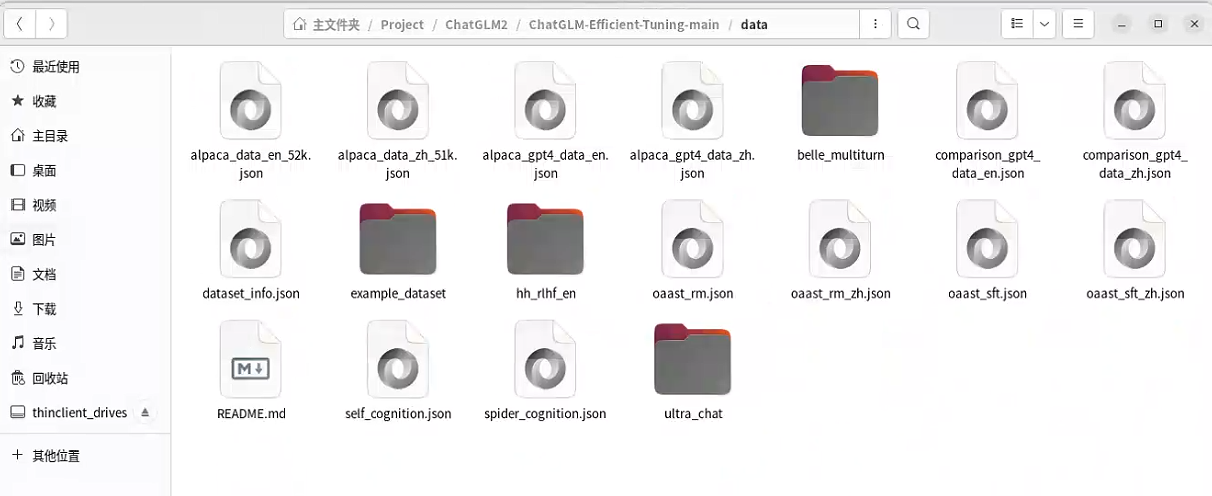
进入data目录下复制self_cognition.json文件名字修改为spider_cognition.json
【self_cognition.json】是模型训练中的一些问答内容,本次微调测试仅仅是修改了该文件中的作者的名字,修改为了“Catmint”一词

在dataset_info.json文件的末尾中添加文件spider_cognition.json,将其添加到模型微调所用到的数据中。

运行如下命令进行模型的微调训练
./simple_finetuning_training.sh --use_v2 --stage sft --do_train --dataset spider_cognition --finetuning_type lora --output_dir output/cognition --per_device_train_batch_size 1 --gradient_accumulation_steps 8 --lr_scheduler_type cosine --logging_steps 10 --save_steps 1000 --warmup_steps 0 --learning_rate 1e-3 --num_train_epochs 10.0 --fp16
以下是该命令的一些解释
-use_v2: 指的是使用某种版本2的模型或框架。-stage sft: 设置了某种阶段为sft。-do_train: 指示脚本进行训练。-dataset spider_cognition: 使用名为spider_cognition的数据集进行训练。-finetuning_type lora: 微调的类型被设置为lora。-output_dir output/cognition: 训练产生的输出(如模型权重和日志)将被保存到output/cognition目录。-per_device_train_batch_size 1: 每个设备的训练批次大小为1。-gradient_accumulation_steps 8: 在执行一次梯度更新之前,累积8个批次的梯度。-lr_scheduler_type cosine: 使用cosine学习率调度。-logging_steps 10: 每10个步骤记录一次。-save_steps 1000: 每1000个步骤保存模型的快照。-warmup_steps 0: 不使用warmup步骤。-learning_rate 1e-3: 设置学习率为0.001。-num_train_epochs 10.0: 设置训练的epoch数量为10。-fp16: 使用半精度浮点数(16位)进行训练,这通常可以加速训练并减少内存使用。

问题
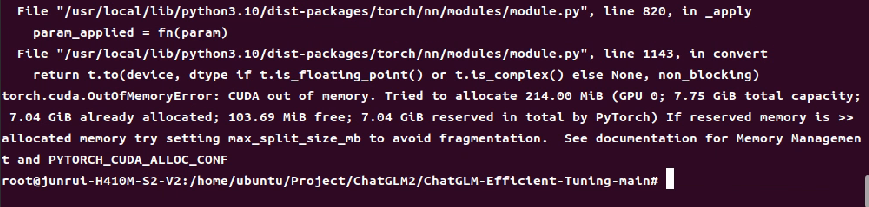
报错信息表示GPU显存不足,LoRA模型微调要求如下

服务器GPU只有8G,而本次模型微调的最低要求是12G显存,无法满足要求。【现有解决方法:1、更换显存更大的显卡以满足需求 2、更换较小的模型进行微调,模型的微调效果会相比而言较差,且微调所使用的脚本需要全部修改,脚本文件需要花费较多时间研究如何修改】
重点内容
本次项目中有给到一些需要重点去关注的数据
/home/Project/ChatGLM2/ChatGLM-Efficient-Tuning-main/examples中的数据
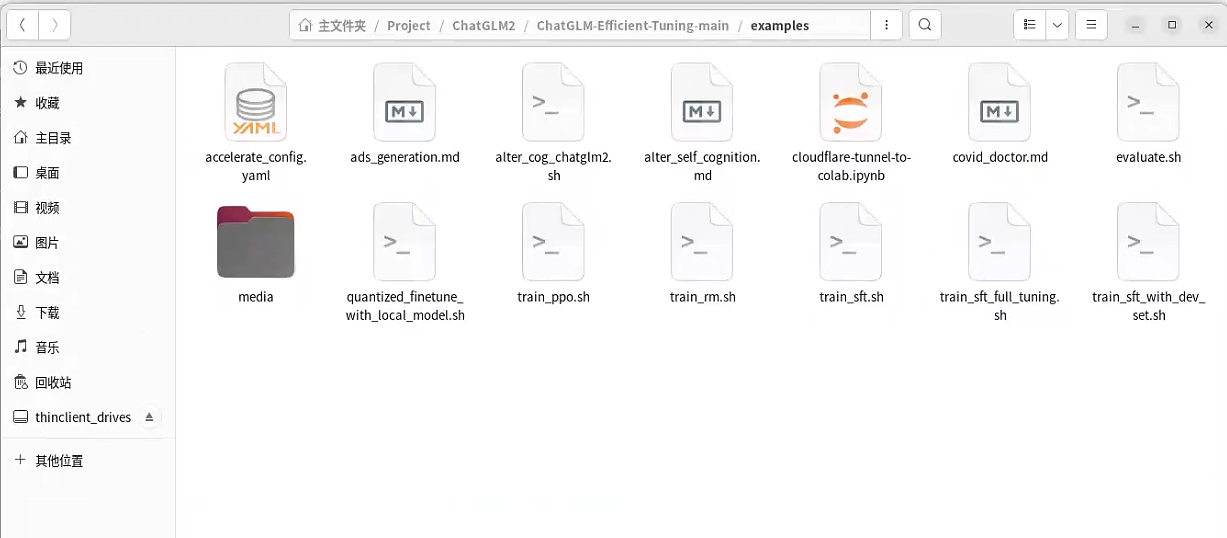
其中covid_doctor.md文件是使用医患对话数据训练新冠诊疗模型的例子的文档
训练的相关数据在media文件夹中
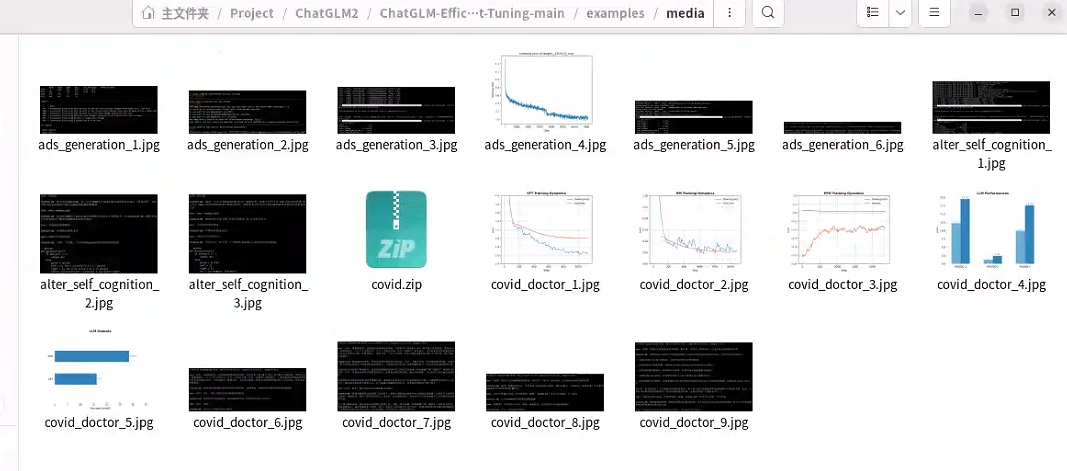
covid.zip压缩文件是医患的对话数据
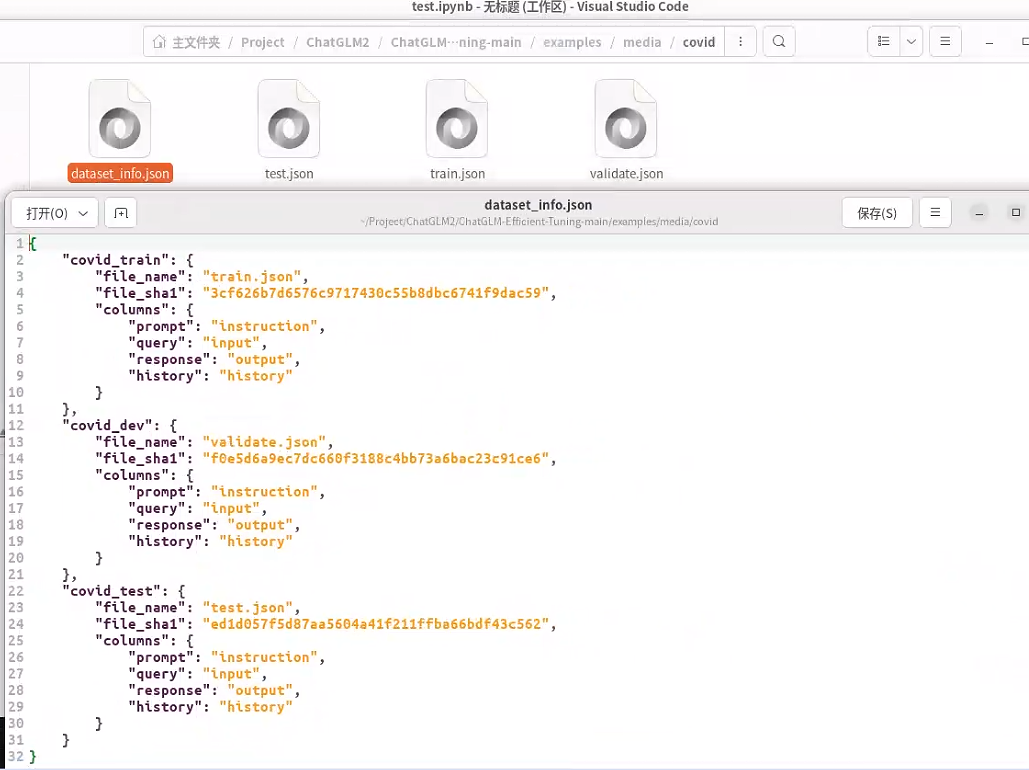
dataset_info.json 文件定义了训练的数据集 test.json、train.json、validate.json
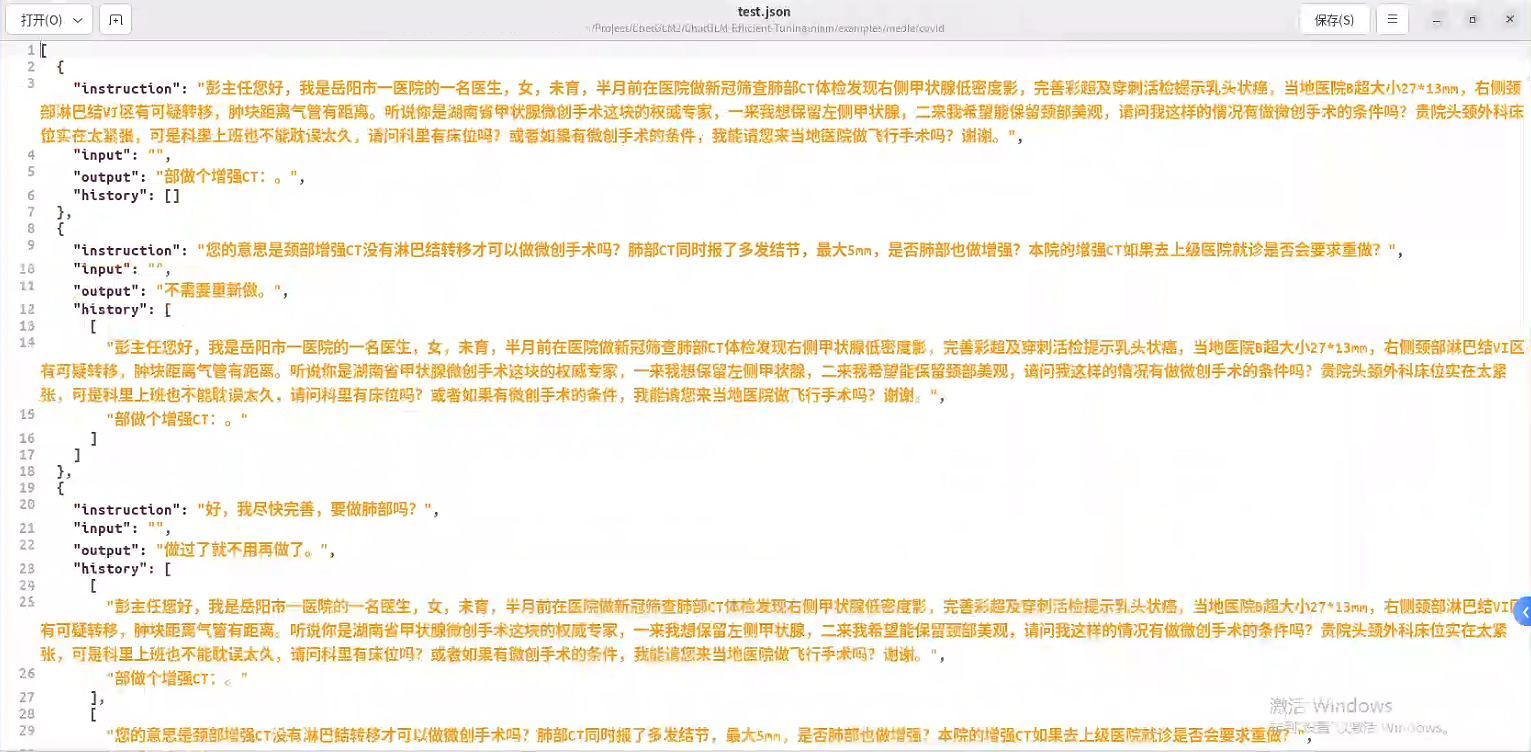
这是医患对话的相关内容
instruction:是用户输入的提问信息
output:是AI输出的回答内容
history:用于记录患者的每一次提问