langchain-supabase-website-chatbot解析网站内容的聊天机器人
项目地址:https://github.com/mayooear/langchain-supabase-website-chatbot
项目依赖下载:yarn install

复制项目中的.env.local.example文件,改名为.env
OPENAI_API_KEY:OpenAI官方网站获取
NEXT_PUBLIC_SUPABASE_URL、NEXT_PUBLIC_SUPABASE_ANON_KEY、SUPABASE_SERVICE_ROLE_KEY:Subpabase官网创建账号后获取
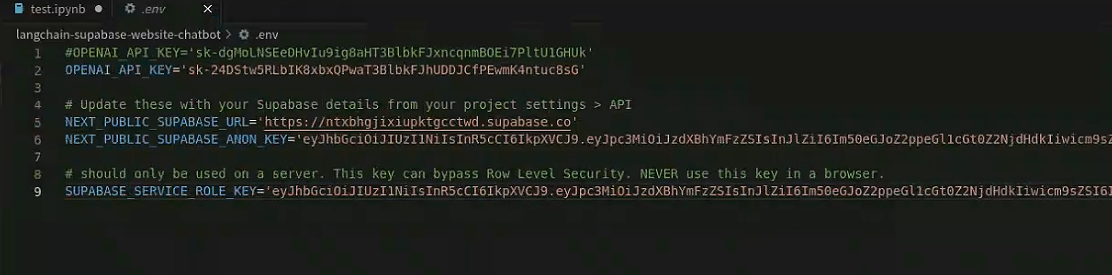
配置.env里的内容,OpenAI Key和Supabase的秘钥
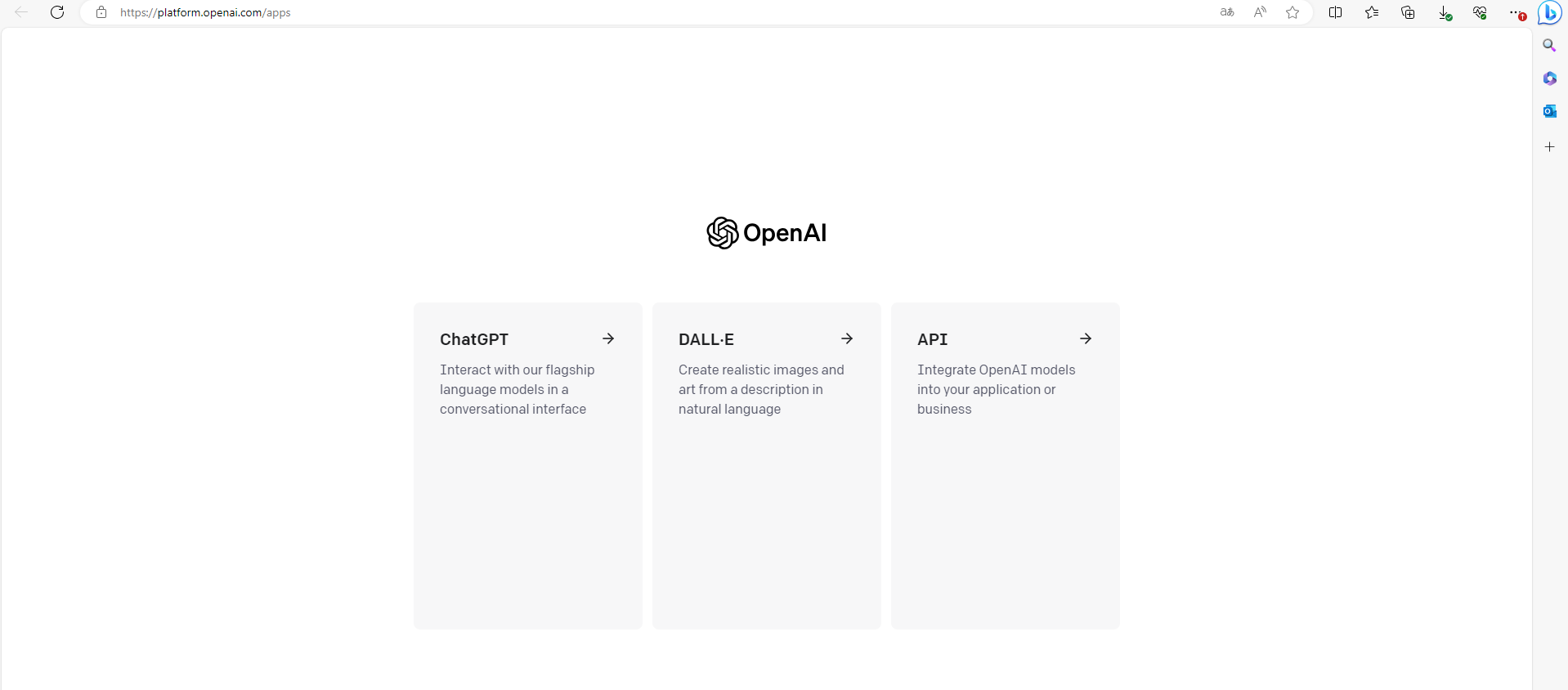
OpenAI官网选择API,在该页面创建获取API Keys【OpenAI Key每个账号免费5$,拥有3个月的试用期,过期后可以创建新的OpenAI账号更换Key,也可以进行续费】
Supabase新建项目
在项目的API选项中获取URL、ANON_KEY、SERVICE_ROLE_KEY
程序的主要运行文件(demo-query.ts、scrape-embed.ts、test.ts)
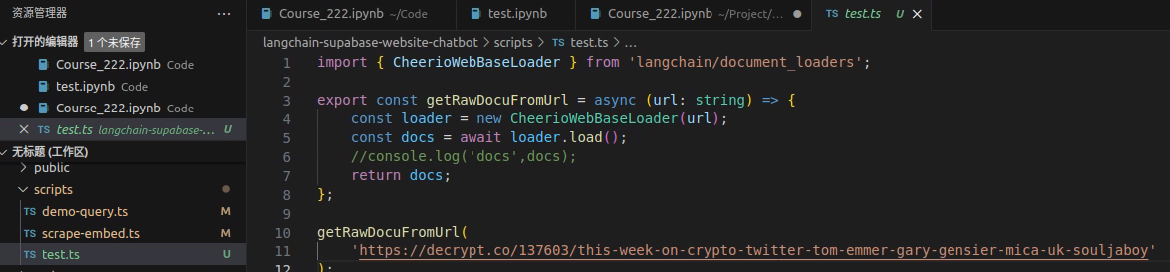
demo-query.ts:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
| import { supabaseClient } from '@/utils/supabase-client';
import { SupabaseVectorStore } from 'langchain/vectorstores';
import { OpenAIEmbeddings } from 'langchain/embeddings';
import { VectorDBQAChain } from 'langchain/chains';
import { openai } from '@/utils/openai-client';
import fetch, { Headers , Request } from 'node-fetch';
global.fetch = fetch;
global.Headers = Headers;
global.Request = Request;
const query = 'how many people die in Derna?';
const model = openai;
async function searchForDocs() {
const vectorStore = await SupabaseVectorStore.fromExistingIndex(
supabaseClient,
new OpenAIEmbeddings(),
);
const chain = VectorDBQAChain.fromLLM(model, vectorStore);
const response = await chain.call({
query: query,
});
console.log('response', response);
}
(async () => {
await searchForDocs();
})();
|

在query变量中可以修改想要提问的问题
scrape-embed.ts:
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
80
| import { Document } from 'langchain/document';
import * as fs from 'fs/promises';
// import { CustomWebLoader } from '@/utils/custom_web_loader';
import type { SupabaseClient } from '@supabase/supabase-js';
import { Embeddings, OpenAIEmbeddings } from 'langchain/embeddings';
import { SupabaseVectorStore } from 'langchain/vectorstores';
import { RecursiveCharacterTextSplitter } from 'langchain/text_splitter';
import { supabaseClient } from '@/utils/supabase-client';
import { urls } from '@/config/notionurls';
import { getRawDocuFromUrl } from './test';
import fetch, { Headers , Request } from 'node-fetch';
global.fetch = fetch;
global.Headers = Headers;
global.Request = Request;
async function extractDataFromUrl(url: string): Promise<Document[]> {
try {
// const loader = new CustomWebLoader(url);
// const docs = await loader.load();
const docs = await getRawDocuFromUrl(url);
return docs;
} catch (error) {
console.error(`Error while extracting data from ${url}: ${error}`);
return [];
}
}
async function extractDataFromUrls(urls: string[]): Promise<Document[]> {
console.log('extracting data from urls...');
const documents: Document[] = [];
for (const url of urls) {
const docs = await extractDataFromUrl(url);
documents.push(...docs);
}
console.log('data extracted from urls');
const json = JSON.stringify(documents);
await fs.writeFile('franknotion.json', json);
console.log('json file containing data saved on disk');
return documents;
}
async function embedDocuments(
client: SupabaseClient,
docs: Document[],
embeddings: Embeddings,
) {
console.log('creating embeddings...');
console.log('storing embeddings in supabase...',docs.length);
console.log('Docs type:', typeof docs);
console.log('Docs to embed:', docs);
await SupabaseVectorStore.fromDocuments(client, docs, embeddings)
console.log('embeddings successfully stored in supabase');
}
async function splitDocsIntoChunks(docs: Document[]): Promise<Document[]> {
const textSplitter = new RecursiveCharacterTextSplitter({
chunkSize: 2000,
chunkOverlap: 200,
});
return await textSplitter.splitDocuments(docs);
}
(async function run(urls: string[]) {
try {
//load data from each url
const rawDocs = await extractDataFromUrls(urls);
//split docs into chunks for openai context window
// const docs = await splitDocsIntoChunks(rawDocs);
const docs = await splitDocsIntoChunks(rawDocs) as Document[];
//console.log('Docs type-----------------------:', typeof docs);
//console.log('Split documents:',docs);
//embed docs into supabase
await embedDocuments(supabaseClient, docs, new OpenAIEmbeddings());
} catch (error) {
console.log('error occured:', error);
}
})(urls);
|
test.ts:
URL表示需要读取的网页
由于LangChain的相关库更新较为频繁,所带的方法也在不停地变动,三个文件都对原项目地址中的代码进行了修改。
将schema.sql文件的内容复制到supabase的SQL Editor处运行
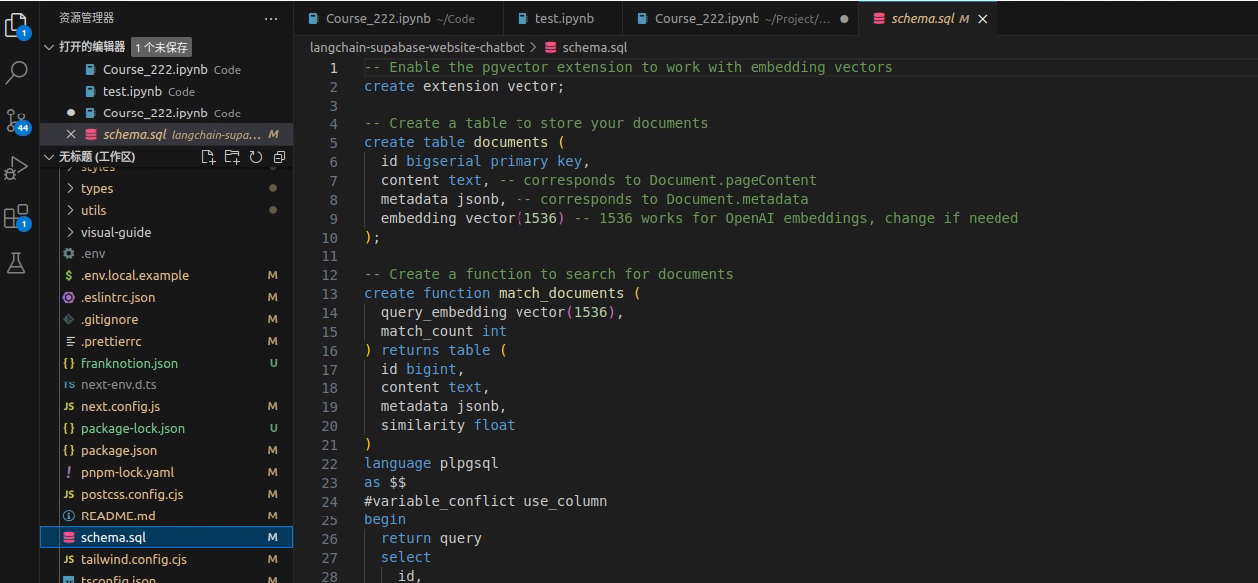
生成documents表(图中数据为后续操作插入)

首先运行scrape-embed.ts文件
npm run scrape-embed.ts

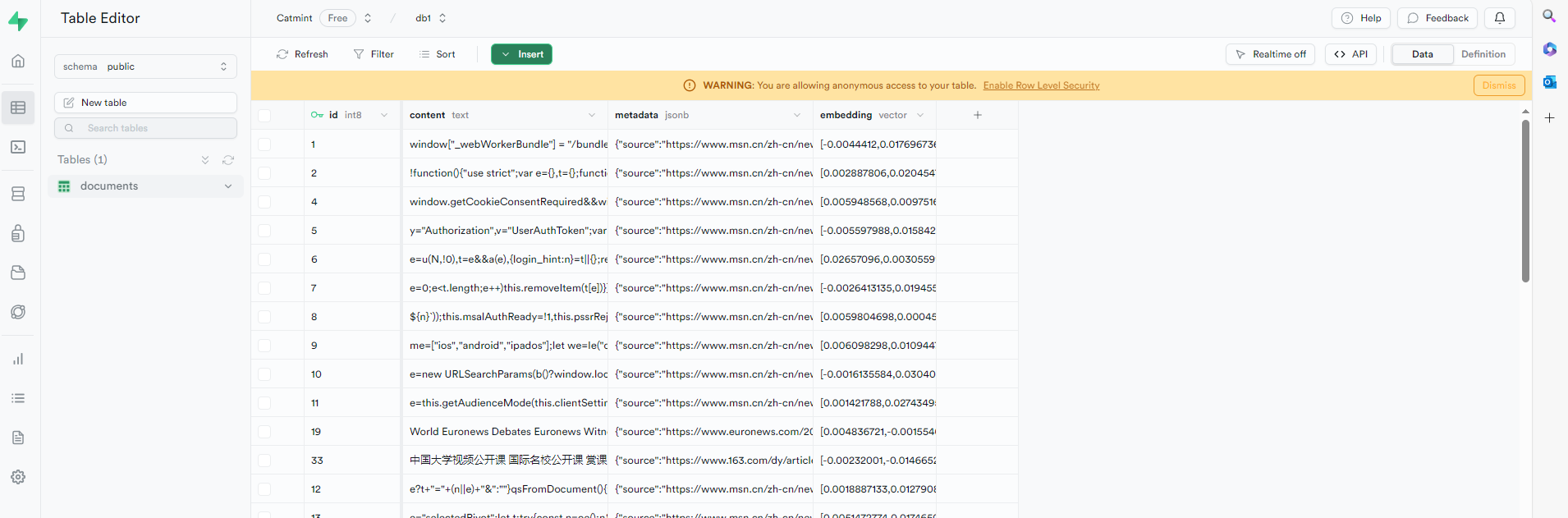
表示内容插入supabases成功,查看数据库确认
运行demo-query.ts文件
npm run demo-query.ts
注意!原项目中缺少对demo-query的运行配置,需要在package.json添加以下标注的代码再执行命令
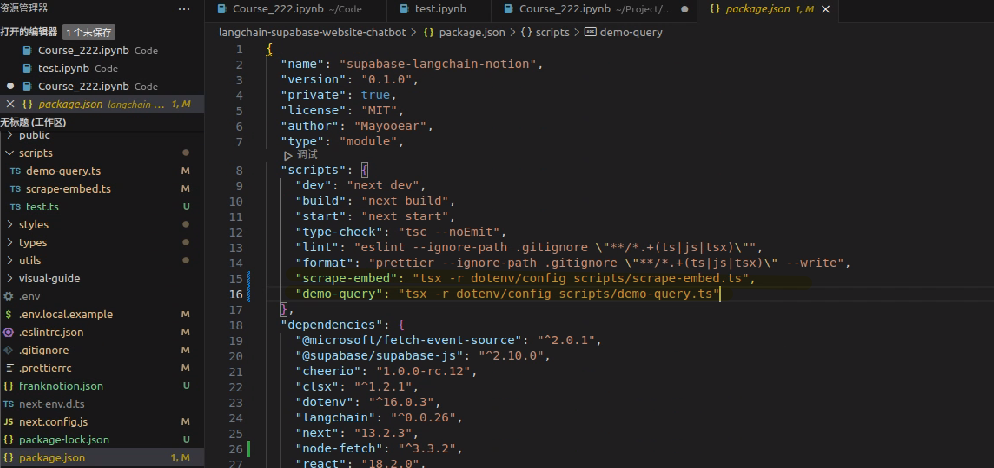
运行结果
提问 const query = 'how many people die in Derna?';
回答如下

需要注意的是有些网站的内容无法正确地解析插入到supabase中,AI对于输入的网站能否正确地读取还未有明确的标准。
性能评价和应用前景收集
项目的数据存储依赖于Supabase,未来是否会收费还未确定。
项目依赖于Open AI 的 api key ,如果使用的话是脱离不了Open AI的相关费用。
提问的问题是写死在demo-query.ts文件中的,使用的话非常不方便,需要修改文件中的提问内容后在终端执行命令才能测试提问结果。
对于一些准确的提问,比如上面所问的 ”Derna的死亡人数是多少“,而我投喂的新闻刚好是有这个内容的,回答才会准确。而如果提问一些别的不太相关的问题,回答一直都是 ”不知道“。回答的效果很差。比起GPT那样的生成文本,这个项目更像是对网站内容进行粗略地读取后存储到Supabase,再执行文件对内容进行索引的一个过程,对于文本的生成能力是很差的。也可能是投喂的网站数量不够大的原因。无法做到许多AI模型训练的庞大数据量。
